


Abstract
The Brief Rating of Aggression by Children and Adolescents (BRACHA) is a 14-item instrument scored by emergency room staff members to assess aggression risk during an upcoming psychiatric hospitalization. In this study, we investigated the inter-rater reliability of the BRACHA 0.9, the latest version of the instrument. After receiving training based on the BRACHA 0.9 manual, 10 intake workers viewed 24 ten-minute videos in which child and adolescent actors portrayed pediatric emergency room patients with low, moderate, or high levels of risk for aggression during an upcoming hospitalization. We then evaluated inter-rater reliability for individual BRACHA items, using three measures of agreement, and reliability for total BRACHA 0.9 scores, using conventional (frequentist) methods and Bayesian techniques for calculating the intraclass correlation coefficient ICC (2,1). Inter-rater reliability for individual items ranged from good to almost perfect, with Kendall's W exceeding 0.75 for eight of 14 BRACHA items. The ICC (2,1) for the total BRACHA 0.9 score was 0.9099, with both conventional and Bayesian methods (95% credible interval 0.8530–0.9533), suggesting an excellent level of overall agreement. The BRACHA appears to be an accurate, highly reliable instrument for assessing the risk of aggression by children and adolescents who are about to undergo psychiatric hospitalization.
Aggression in children during psychiatric hospitalization is a common phenomenon that can harm the physical and mental health of both patients and clinical staff members.1,–,5 Better methods for assessing inpatients' risk of acting aggressively may help clinicians institute treatment measures that would improve hospital safety. Although some instruments appear useful for rating severity and type of pediatric aggression6 (e.g., the Overt Aggression Scale (OAS)) and for assessing violence risk in adult psychiatric inpatients,7,8 mental health professionals do not yet have a well-validated tool for assessing the potential for violence among children during short-term psychiatric hospitalization.9
Recently, Barzman and colleagues9 showed that the Brief Rating of Aggression by Children and Adolescents (BRACHA) may help clinicians rapidly assess the risk of aggression by child and adolescent psychiatric inpatients. The BRACHA is a 14-item instrument scored by emergency room staff members using information that is consistently available, even during short, high-pressure evaluations. In this initial accuracy study, Barzman and colleagues showed that the sum of the 14 BRACHA items was directly related to the risk of aggression by children and adolescents during psychiatric hospitalization. This finding suggests that the BRACHA may help admitting clinicians differentiate between patients of relatively low and high aggression risk, which could help inpatient staff members plan treatment, reduce injuries, and reduce the need for restraint. To date, however, no information about the BRACHA's inter-rater reliability is available, an important consideration, given that the usefulness of the instrument would depend in part on there being consistency among ratings performed by various emergency room workers. We investigated the inter-rater reliability of the latest version of Barzman and colleagues' instrument, the BRACHA 0.9.
Methods
This study received approval from the Institutional Review Board at Cincinnati Children's Hospital Medical Center, which granted a waiver of consent because the study was deemed an exempt research project.
Instrument
The BRACHA 0.9 contains some minor modifications from previously described versions of the BRACHA.9 As was true of previous versions of this instrument, the BRACHA 0.9 is a 14-item instrument that directs evaluators to score 12 historical and behavioral items and two clinical observations. However, the BRACHA 0.9 items are reworded or rephrased to improve clarity and reliability. In previous versions of the BRACHA, evaluators simply assigned ratings of present/yes or absent/no, but in the BRACHA 0.9, several items allow three levels of response (Table 1), a scoring option often used in psychological instruments. We hoped that by allowing graded or intermediate response options, evaluators would not have to shoehorn ambiguous findings or mischaracterize mild expressions of clinical problems as simply present or absent. We also believed that graded responses might be conducive to improved single-item and full-scale reliability and (as we hope to investigate in future studies) that item intensity might be used to increase the BRACHA's predictive power.
Abbreviated BRACHA 0.9 Items and Response Options*
Materials and Procedures
We developed a BRACHA 0.9 training manual to help psychiatric intake personnel apply criteria and interpret information consistently. (Readers may obtain a copy of the manual by writing to the first author). We also produced 38 short videos in which the first author interviewed actors who portrayed child and adolescent patients and their legal guardians. The child, adolescent, and adult actors came from two acting classes at local schools. Actors received short descriptions of clinical scenarios derived from actual clinical presentations of children and adolescents, along with instructions to respond to the interviewer's questions using improvisation. Two acting coaches were available to provide assistance and directing to make the videos more realistic. The videos were approximately 10 minutes long and portrayed minors with low, moderate, or high levels of risk for aggression or violence. In making the videos, participants attempted to simulate conditions and clinical practices applied during a short emergency room interview. Although the interviewer made inquiries about clinical problems with BRACHA items in mind, the interviewer did not specifically read and request responses to items in the BRACHA.
Ten emergency room social workers from the Psychiatric Intake Response Center (PIRC) of Cincinnati Children's Hospital Medical Center volunteered to be raters in the study. These raters had 2 to 12 years of experience in conducting evaluations on children and adolescents in our hospital's emergency department. Each rater received one hour's training from the first author that included discussion of the training manual and the BRACHA 0.9 items, coupled with viewing a sample video that was not used for the study. The raters scored the sample video with the first author to foster consensus on ratings, and he answered questions that the raters had about the instrument.
Data Sample
A power analysis (a two-tailed test with 80% power and α = .05) showed that 10 raters would have to view 23 videos to detect a reliability difference between intraclass correlation coefficients (ICCs) of 0.4 (which would be considered poor) and 0.7 (the lowest overall reliability level that we considered acceptable).10 We ultimately selected 24 of the 38 videos for this rating study because they showed a range of aggression risk levels for an age group ranging from preschoolers to adolescents. We culled 14 videos, either because the coverage of risk factors was incomplete or because risk level and age overlapped with the other videos. The 10 raters viewed all 24 videos and scored the 14 BRACHA items solely on the basis of the content of each video (and without other collateral information), using an in-house computer for viewing and recording item scores electronically. Raters received $25 as compensation for their participation time.
Previous work showed that children's ages had an inverse relationship to risk of aggression, independent of the 14 BRACHA interview items, and age was therefore an independent factor in previous BRACHA formulae.9 The present study included mock patients with ages ranging from 6 to 18 years. In this study, we focused primarily on agreement regarding the 14 items shown in Table 1, but we also used Bayesian techniques (explained further in the Data Analysis section) to evaluate the potential impact of age on the ratings.
Statistical Analysis
After raters finished viewing and scoring the vignettes, the first author and support staff printed each set of results and entered the data by using a double-entry checking method that allowed for verification and correction before analysis. Data sheets were then stored in a secure area.
Because statisticians disagree on optimal methods of evaluating inter-rater agreement, we used three measures of inter-rater reliability for individual BRACHA items: Kendall's coefficient of concordance W,11,12 Fleiss' generalized kappa (κF),13 and Gwet's AC statistic.14 Kendall's W is a nonparametric measure of agreement applicable to ranked outcomes or judgments. As originally developed, κF and Gwet's AC statistic apply to nominal rather than ranked or ordinal data, so for three-level items, we evaluated these statistics applying the quadratic weighting method recommended by Gwet. To calculate Kendall's W, we used the on-line StatTools calculator developed by Allan Chang, available at http://www.stattools.net/StatToolsIndex.php. We calculated κF and AC statistics using the downloadable Excel-based Agreestat software, available at http://www.agreestat.com/agreestat.html.
For purposes of this study, we calculated total BRACHA 0.9 scores using equal weightings for each questionnaire item, with two-option items scored 0 or 1, and three-option items scored 0, ½, or 1. BRACHA 0.9 scores could thus range from 0 to 14. In cases in which a rater did not score one or more BRACHA items (which occurred 11 times in 14 × 10 × 24 = 3,360 instances; 0.33%), we computed the rater's prorated total BRACHA 0.9 score for that vignette as 14 times the average of the answered items.
We evaluated BRACHA 0.9 reliability using conventional (frequentist) methods and Bayesian techniques implemented with WinBUGS.15,16 We obtained the frequentist ICC (2,1), the appropriate statistic when, as in this case, all subjects are rated by the same raters who are assumed to be a random subset of all possible raters,17 for total-score agreement using the on-line calculator available at the Chinese University of Hong Kong website (http://department.obg.cuhk.edu.hk/researchsupport/IntraClass_correlation.asp).
Bayesian estimation methods summarize knowledge about unknown parameters using posterior distributions of the probability that a parameter has a particular value, given the observed data and a prior probability of the parameter's value. When priors are noninformative, Bayesian and frequentist methods yield similar inferences.18 An advantage of Bayesian estimation, however, is that it provides a proper basis for statements such as: the probability that the ICC is between x and y is 95 percent.
WinBUGS allows users to specify a Bayesian model and generate draws from the joint posterior distribution of unknown parameters using Markov chain Monte Carlo iteration methods.19,–,21 One discards values from an initial set of burn-in iterations (chosen to be large enough to assure model convergence) to make inferences about model parameters from subsequent iterations. For this study, we adopted methods described by Broemeling22 and modified his WinBUGS code to make several inferences about Bayesian measures of agreement, sampling from the last half of a three-chain, 200,000-iteration run for each tested model. An example of our WinBUGS code appears in Appendix A.
Results
Individual Items
Table 2 summarizes results of our evaluation of inter-rater agreement for individual BRACHA items. For all items, the three test statistics imply that agreement exceeds chance levels, in most cases by a large margin. Item 7 appears to be an outlier, if one looks at the Fleiss kappa value κF alone, because the 95 percent confidence interval for this statistic just exceeds the random range. We note, however, that the base rate for Item 7 was low (2 of 24 videos), a situation in which κF is known to perform poorly. The AC statistic does not share this flaw,14 and, along with Kendall's W, it suggests that Item 7 has respectable reliability.
Inter-rater Reliability for Individual BRACHA Items
Figure 1 depicts the 10 raters' prorated total BRACHA 0.9 scores as box-and-whisker plots of the five-number summaries (smallest score, lower quartile, median score, upper quartile, and largest score) for all 24 videos. The mean + SD of the raters' scores for each video appears along the vertical axis. (To facilitate apprehension of these data, we ordered the 24 videos along the vertical axis from smallest to largest mean BRACHA 0.9 score.) Figure 1 shows that the largest standard deviation of raters' scores was 1.6 points, and for 13 videos, the standard deviation was less than 1 point, findings that informally suggest good inter-rater agreement.

The 10 raters' prorated total BRACHA 0.9 scores for the 24 videos. The scores were a summary of five numbers: smallest score, lower quartile, median score, upper quartile, and largest score.
Total BRACHA 0.9 Score
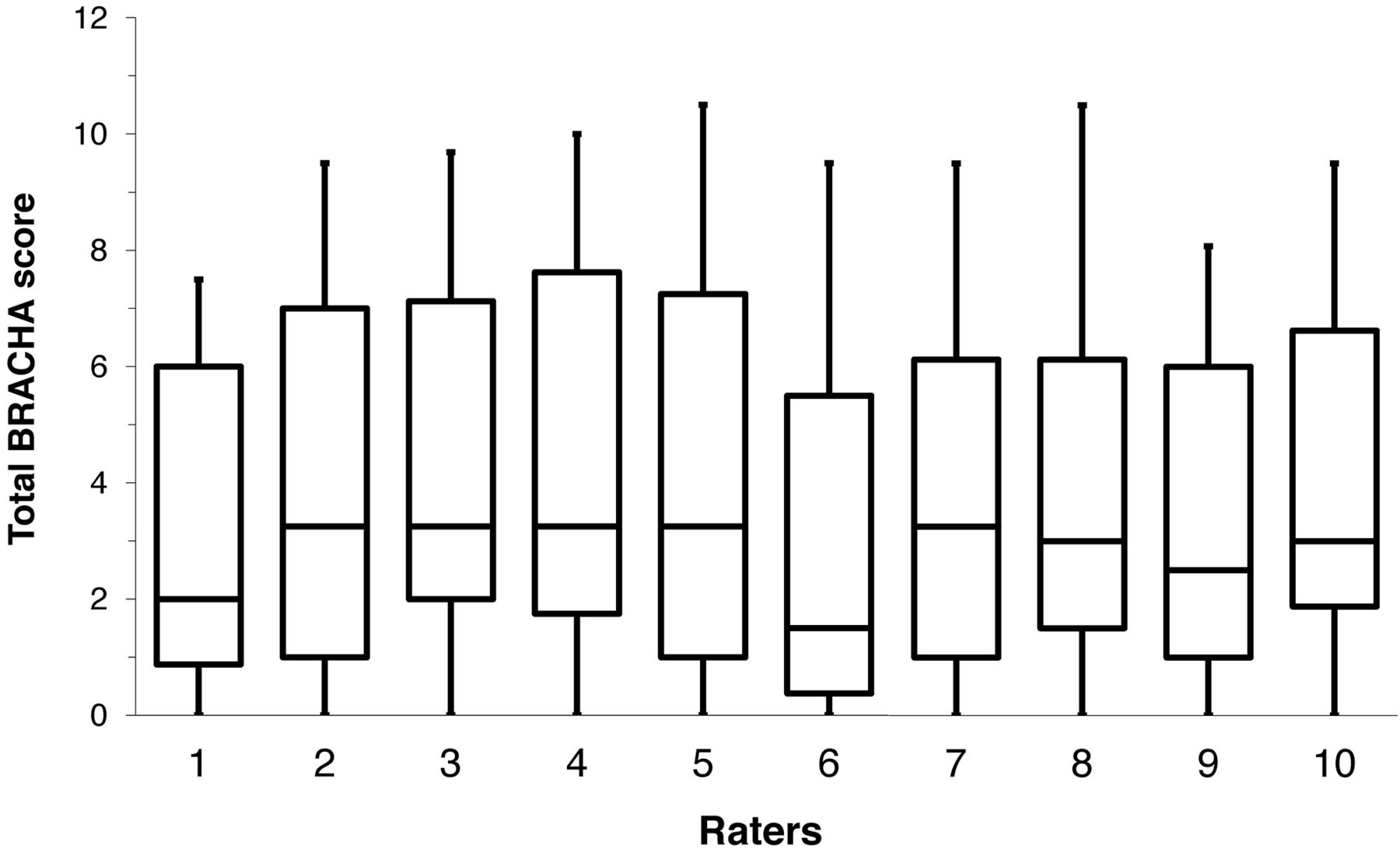
Table 3 provides the results from our ICC (2,1) calculations for the BRACHA 0.9. Using conventional (frequentist) statistical methods, the ICC (2,1) was 0.9099, which implies excellent overall agreement among video raters. Figure 2, however, suggests that Raters 1 and 6 tended to assign lower scores than did the other raters. We evaluated this possibility and its impact by using Bayesian methods,22 implemented via three data models for the raters' prorated BRACHA 0.9 scores.
Calculation of the ICC, Conventional Method
Plots of scores assigned by each rater show that Raters 1 and 6 tended to score videos lower than the others.
In Model 1,
Bayesian Calculation of the ICC
A. Model 1:

B. Model 2:

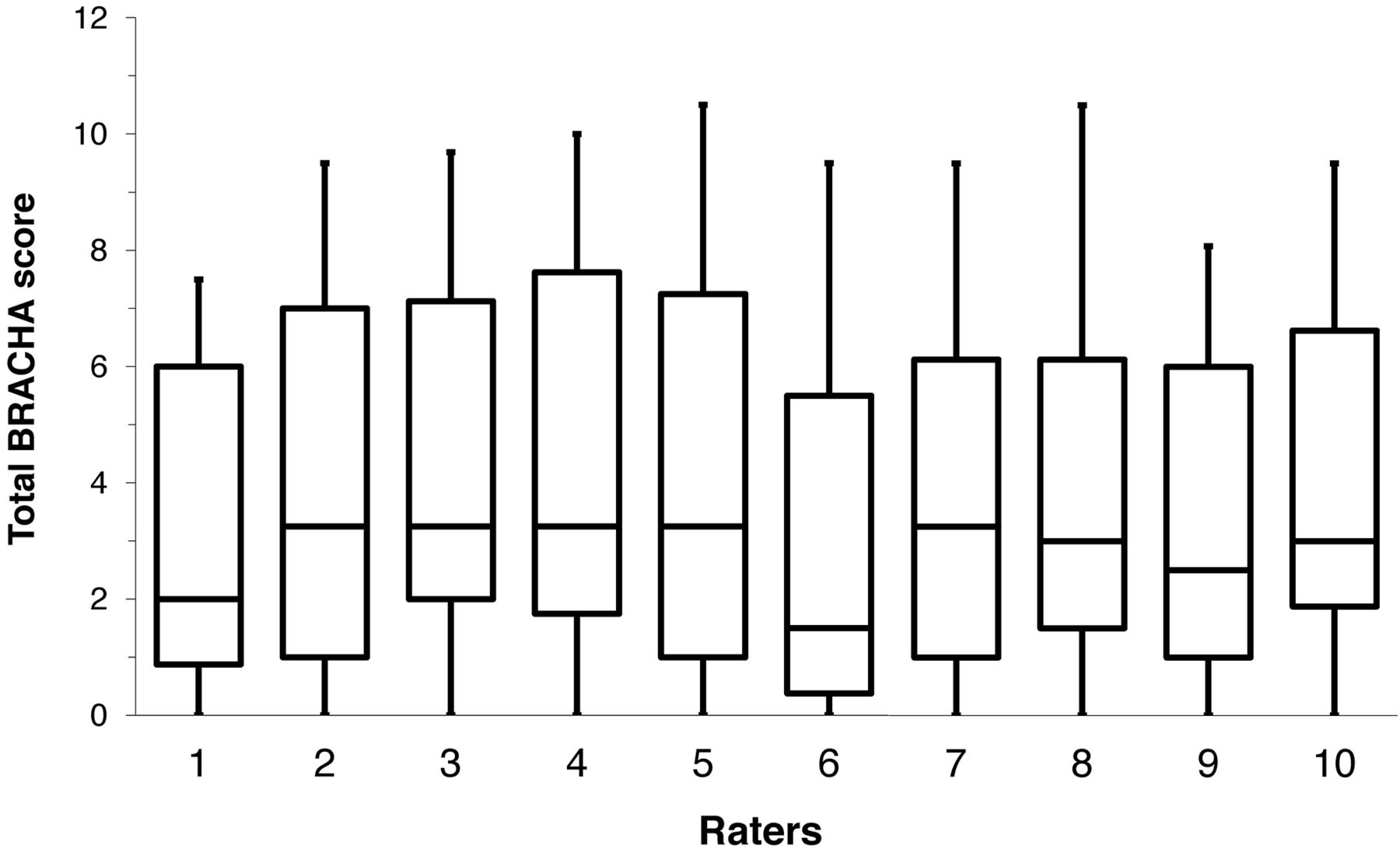
ICC=σ2aσ2a+σ2b+σ2ω
C. Model 3:
In Model 2,
As we noted earlier, Barzman and colleagues9 found that age had an inverse relationship to inpatient aggression, and we therefore wondered whether subjects' age might be a factor in the scores that raters assigned videos. Model 3 expresses this potential relationship as
Discussion
We found that the inter-rater reliability of individual BRACHA items ranged from good to almost perfect, when using the criteria of Landis and Koch,23 and agreement for the total BRACHA score (ICC (2,1) = 0.9099) qualified as excellent according to the criteria of Cicchetti and Sparrow.24 We note also that our reliability findings concerning the BRACHA 0.9 compare favorably to the inter-rater agreement reported for other well-studied adult risk assessment instruments. For example, Douglas and Reeves25 reported that in 36 studies of the HCR-20, the median reliability was 0.85 (range, 0.67–0.95); Anderson and Hanson described studies reporting ICCs of 0.87 for the Static-99.26 Our findings also compare favorably to those of Almvik and colleagues27 who, in their study of the Brøset Violence Checklist (a six-item adult inpatient assessment instrument), reported individual item kappas of 0.48−1.0 and 0.44 for the total BVC score.
Our reliability evaluation methods differed from those in most other reliability studies of instruments used to assess risk of aggression. In our study, intake workers viewed video recordings of actors portraying emergency room pediatric patients and their adult guardians. This study design had several advantages: it allowed us to examine reliability under evaluation scenarios with children and adolescents of various ages, with diverse levels of aggression and with a large (and therefore more representative) group of raters. In addition, the raters based their judgments on clinical scenarios derived from actual case presentations of child and adolescent psychiatric patients. This study thus showed that scoring of BRACHA items is reasonably reliable when raters receive information of the sort typically obtained in an emergency room or an urgent office consultation.
Because the BRACHA is intended for use in rapidly assessing emergency room patients for whom hospitalization is anticipated, it would have been impossible to carry out a multirater reliability study under conditions of actual use. By giving raters the same information on which to base ratings, our study's video-scenario design eliminated potential errors in information-gathering that might obscure intrinsic reliability of individual items themselves (and the resulting total BRACHA score).
A real-life reliability study would require having multiple raters interview the same patients in the emergency room, together or separately, something that would probably be impossible to carry out and that would certainly raise questions of ethical practice. Yet we recognize that this unavoidable limitation in our study design prevented us from learning how the information-gathering process affected ratings, which is an important feature of inter-rater reliability. Using actors who worked from scenarios presented in videos designed specifically to capture items relevant to the BRACHA may have enhanced inter-rater agreement above what one would obtain if multiple raters could elicit information from the same subjects under the typical battle conditions of the emergency room.
However, the BRACHA items should form part of an initial psychiatric interview, so we believe that the use of videos depicting an initial psychiatric interview was an appropriate means of assessing important features of the instrument's reliability. Also, most of our raters viewed multiple consecutive videos during work hours in a noisy environment that was at least as distracting as being in a quiet interview room in the emergency department. Had the raters conducted their own detailed, individual interviews of actual patients and been able to seek information specific to the BRACHA items, and had the raters then combined this information with the types of collateral information that often is available (e.g., chart reports on previous hospitalizations), they might have improved factual ascertainment and achieved better reliability parameters than the results we developed from having raters view multiple consecutive short videos.
Conclusions
The BRACHA appears to be a highly reliable instrument for assessing the risk of aggression in children and adolescents in hospitals. This finding, coupled with earlier findings of good accuracy,9 suggests that the BRACHA can help mental health professionals identify children and adolescents with heightened risk of aggression during psychiatric hospitalization.
Appendix A.
WinBUGS Code for Bayesian Estimation of the ICC

Footnotes
This study was supported by the American Academy of Psychiatry and the Law's Institute for Education and Research.
Disclosures of financial or other potential conflicts of interest: None.
- © 2012 American Academy of Psychiatry and the Law


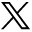


{kind=link}
{kind=link}
{kind=link}